22.3. Snelheid van toegang
Moderne systemen hebben vaak simultaan toegang tot gegevens nodig. FTP en webservers kunnen bijvoorbeeld duizenden simultane sessies onderhouden en hebben vaak meerdere 100 Mbit/s verbindingen met de rest van de wereld. De benodigde gegevensdoorvoer is dan groter dan de meeste schijven kunnen leveren.
Huidige schijven kunnen gegevens sequentieel overdragen met ongeveer 70 MB/s, maar deze snelheid heeft geen waarde in een omgeving waar onafhankelijke processen toegang tot de schijf hebben. In zo'n situatie is het interessanter om vanuit het standpunt van de schijfstuurprogramma te kijken: de belangrijkste parameter is dan de belasting die een bepaalde gegevensoverdracht op het stuurprogramma plaatst. Met andere woorden: wat is het tijdsbeslag van een gegevensoverdracht op te schijf?
Bij elke gegevensoverdracht moet de schijf eerst zijn kop positioneren, wachten tot de eerste sector onder de kop doorkomt en vervolgens de overdracht starten. Deze acties duren bijzonder kort. Het heeft geen enkele zin om ze te onderbreken.
Neem een overdracht van ongeveer 10 kB: de huidige generatie high-performance schijven kan de kop in 3.5 ms plaatsen. De snelste schijven draaien met 15.000 toeren per minuut, dus de gemiddelde rotatie vertraging (een halve omwenteling) bedraagt 2 ms. Met 70 MB/s de overdracht zelf duurt ongeveer 150 μs, bijna niets vergeleken met de tijd die verloren is gegaan aan het positioneren. In zulke gevallen daalt de gegevensoverdracht naar iets meer dan 1 MB/s en is dus duidelijk afhankelijk van de grootte van de over te dragen gegevens.
De traditionele en logische oplossing voor dit probleem is “meer schijven”: in plaats van één grote schijf, meerdere kleine schijven met een zelfde totale opslagcapaciteit. Iedere schijf is in staat om onafhankelijk de kop te plaatsen en de gegevens over te dragen, dus de effectieve doorvoer neemt toe met een factor bijna gelijk aan het aantal schijven.
De exacte verbetering van de doorvoer is natuurlijk kleiner dan het aantal schijven, want hoewel iedere schijf in staat is om parallel de gegevens over te dragen, er is geen garantie dat de gegevens gelijk over de schijven verdeeld is. De belasting op de ene schijf zal dan ook groter zijn dan op de andere schijf.
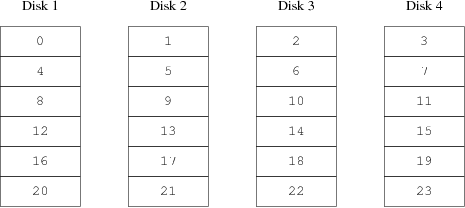
Een gelijke belasting van de schijven is in grote mate afhankelijk van de manier waarop gegevens over de schijven zijn verdeeld. In het volgende stuk is de opslag van een virtuele schijf voor te stellen als een verzameling sectoren die met een nummer aangesproken kan worden, net als bladzijden in een boek. De meest voor de hand liggende methode om een virtuele schijf te maken is het achter elkaar plakken van de fysieke schijven. Een virtueel boek zou dan opgebouwd zijn uit verschillende achter elkaar zittende fysieke hoofdstukken. Deze methode heet aaneenschakelen (“concatenation”) en heeft het voordeel dat schijven verschillend van grootte kunnen zijn. Dit werkt prima als toegang tot de gegevens gelijk verdeeld is over de hele gegevensverzameling. Als die toegang beperkt is tot een klein deel van de gegevensverzameling, is de snelheidsverbetering een stuk kleiner. Figuur 22-1 laat de manier zien hoe aaneengeschakelde schijven hun gegevens opslaan.
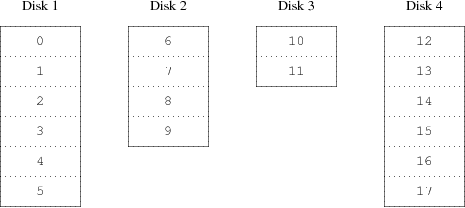
Een andere methode is het verdelen van de totale opslag van de virtuele schijf in kleinere stukjes van gelijke grootte en ze achter elkaar op verschillende fysieke schijven op te slaan. Bijvoorbeeld: de eerste 256 sectoren worden op schijf 1 opgeslagen, de tweede 256 sectoren op schijf 2 enzovoort, tot de laatste schijf is gebuikt, waarna weer bij schijf 1 verder wordt gegaan, net zolang tot de schijven vol zijn. Deze methode heet verdelen (“striping”) of RAID-0. [1]. Bij RAID-0 kost het iets meer moeite om de gegevens te vinden en het kan extra I/O belasting met zich meebrengen als gegevens zijn verdeeld over verschillende fysieke schijven. Het kan echter ook zorgen voor een constantere belasting van die schijven. Figuur 22-2 geeft weer hoe RAID-0 schijven hun gegevens opslaan.